Motivation
Attention has become fundamental in machine learning models from transformers to graph neural networks (GNNs). However, its computational cost remains a bottleneck as we scale in sequence length and graph size. While dense and block-sparse attention have benefited from hardware-aware algorithm design (e.g., FlashAttention), sparse attention—essential for graph-based learning and dynamic sparsity patterns—remains under-optimized on modern hardware accelerators.
This inefficiency is especially pronounced on GPUs with tensor cores, which deliver peak throughput for dense matrix multiplications with strict operand shapes. Sparse operations involve irregular memory accesses and unstructured computation, making them poorly suited for current tensor core design. As a result, tensor cores remain largely underutilized for sparse workloads.
Prior efforts fall into two categories:
- Individual kernel optimizations — improving SDDMM and/or SpMM in isolation, but incurring unnecessary data movement when intermediate results are materialized in global memory.
- Kernel fusion — reducing memory traffic by combining operations, but existing fused kernels target only CPUs or CUDA cores, leaving tensor core acceleration untapped.
No existing work fuses the 3S operations while targeting tensor cores — until Fused3S.
The 3S Computational Pattern
The 3S pattern computes sparse attention as:
O = softmax(QKT ⊙ A) V
where Q, K, V, O ∈ ℝN×d are dense matrices and A ∈ ℝN×N is a sparse matrix defining attention patterns (e.g., adjacency or masking). This decomposes into three operations:
- SDDMM — Compute attention scores S = QKT ⊙ A, where the dense product is computed only for non-zeros in A.
- Softmax — Normalize scores row-wise: E = softmax(S).
- SpMM — Aggregate output: O = EV.
This pattern appears across Graph Attention Networks (GAT), Graph Transformers (GT), and Sparse Transformers — all sharing the same 3S bottleneck on modern hardware.
Key Contributions
1. Binary Sparse Block (BSB) Format
We introduce the Binary Sparse Block (BSB) format to efficiently map a sparse matrix onto tensor cores. BSB extends prior tensor-core-aware formats but reduces overhead by encoding sparsity with a fixed-size bitmap instead of integer indices.
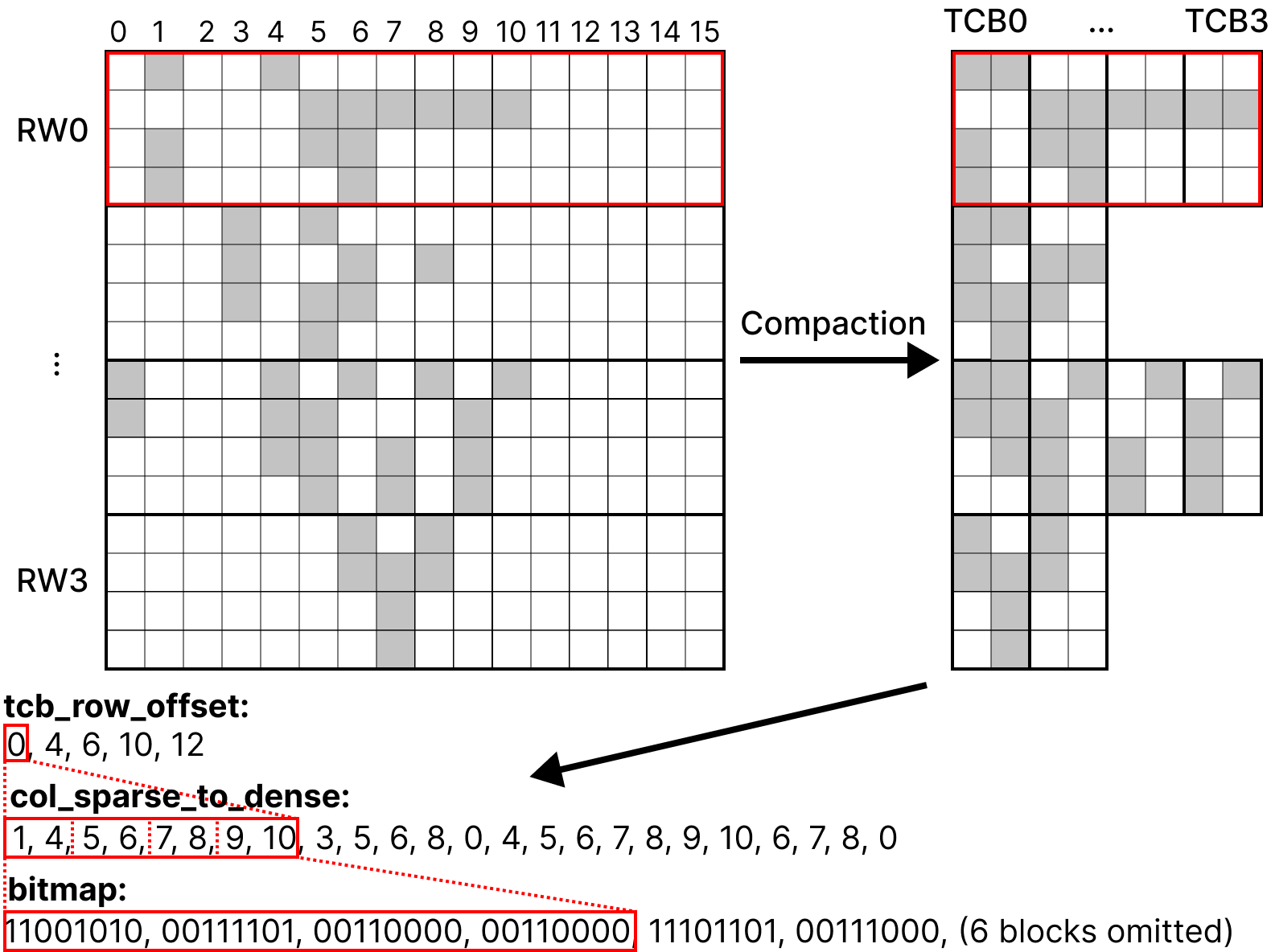
The construction proceeds as:
- Divide the sparse matrix into row windows of size r.
- Within each row window, eliminate columns containing only zeros to increase compute density.
- Partition the compacted row window into tensor core blocks (TCBs) of shape r × c aligned with MMA tile sizes (e.g., 16 × 8).
- Store a bitmap encoding the sparsity pattern in each TCB (128 bits for a 16×8 block), eliminating indexing overhead.
2. Fused On-Chip Algorithm
Fused3S fuses SDDMM, softmax, and SpMM into a single GPU kernel to reuse intermediate results in registers and shared memory, avoiding costly global memory round-trips.
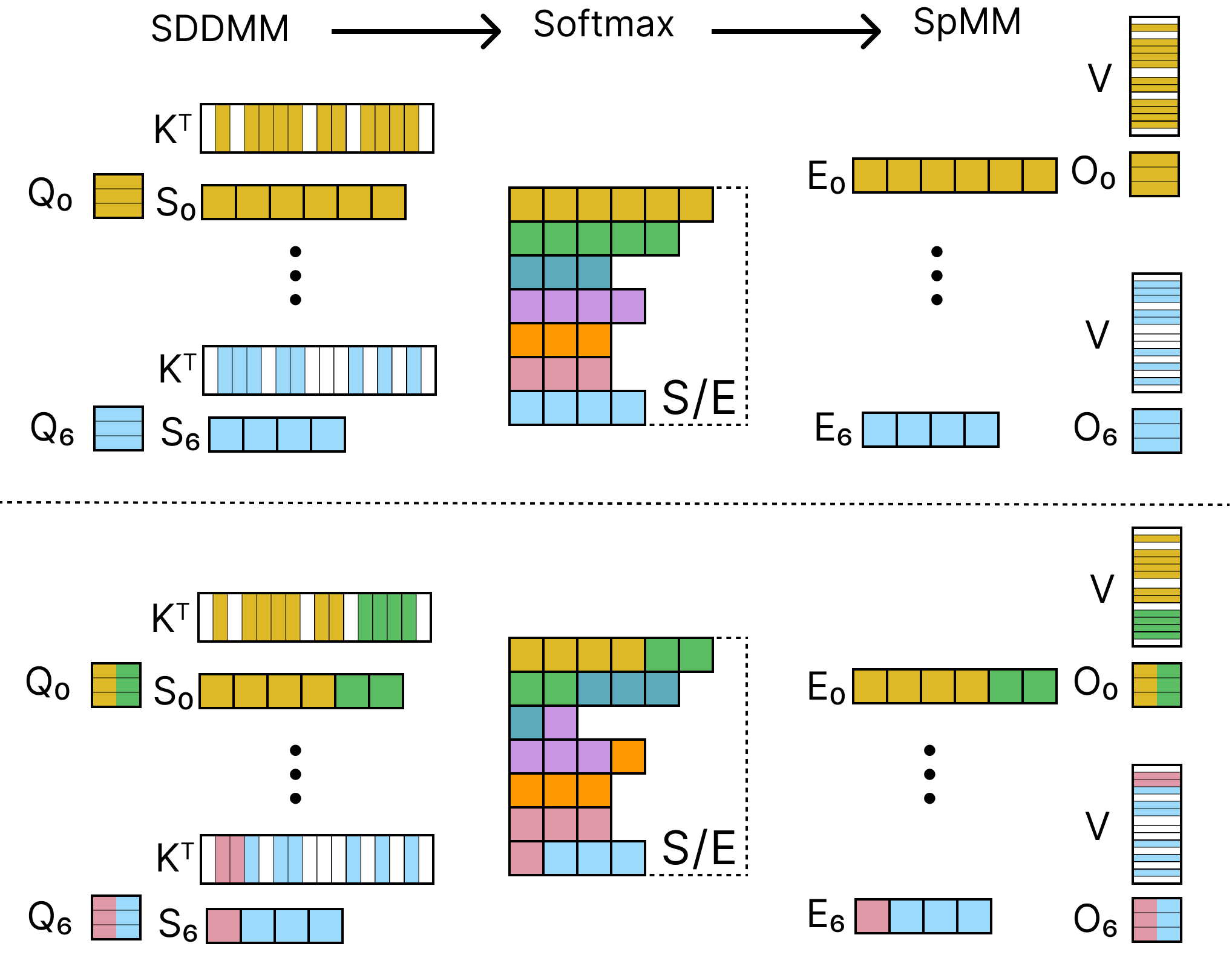
We adopt node-parallel fusion where each thread block handles a row window, keeping all softmax and SpMM data local. To address load imbalance in graphs with irregular degree distributions, we apply row window reordering — sorting row windows by decreasing TCB count so that the heaviest work is scheduled first when more parallelism is available.
3. Warp Partitioning and Register Remapping
Within each thread block, we use a split-column warp partitioning strategy where each warp computes independent tiles of the output, eliminating inter-warp synchronization.
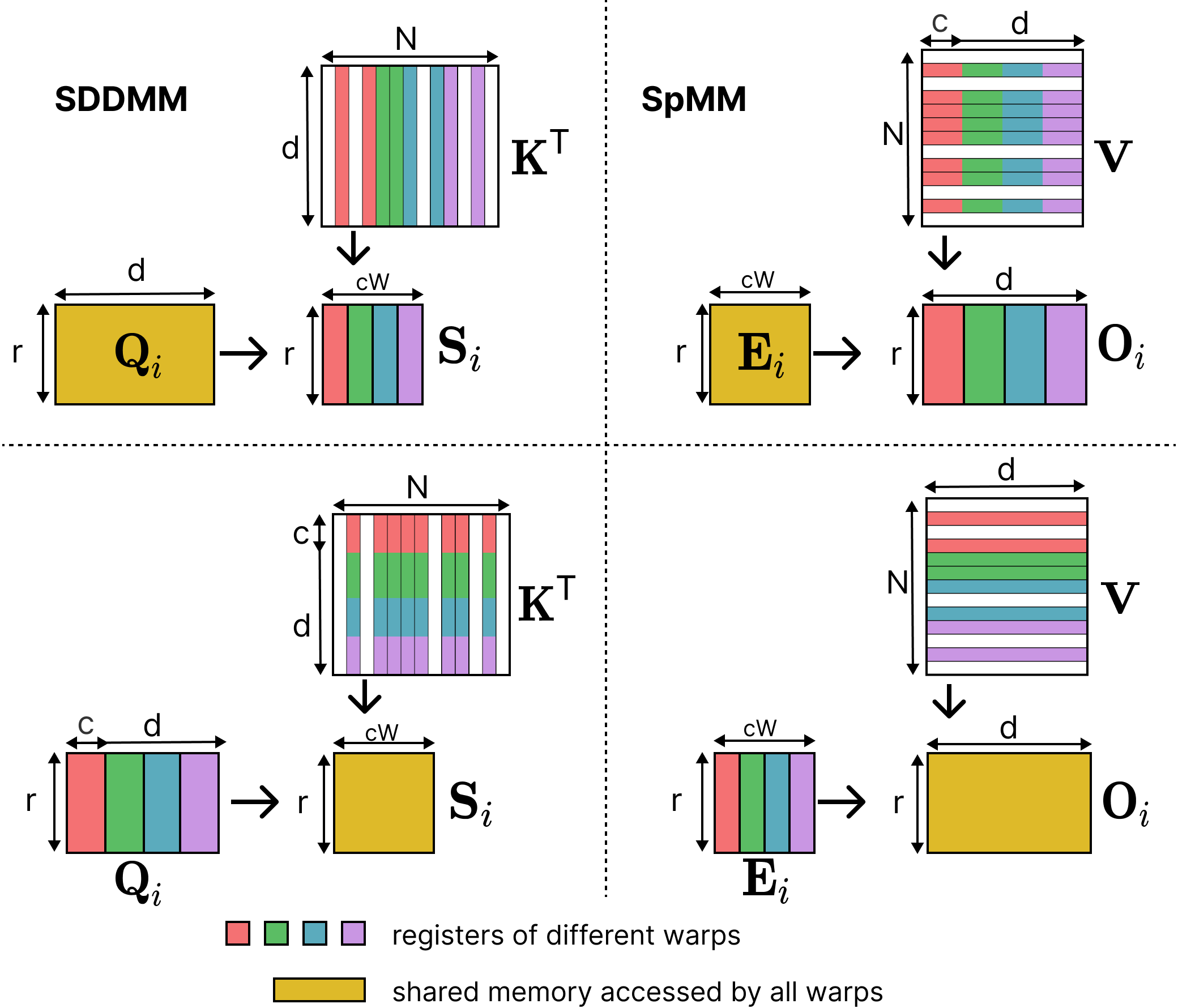
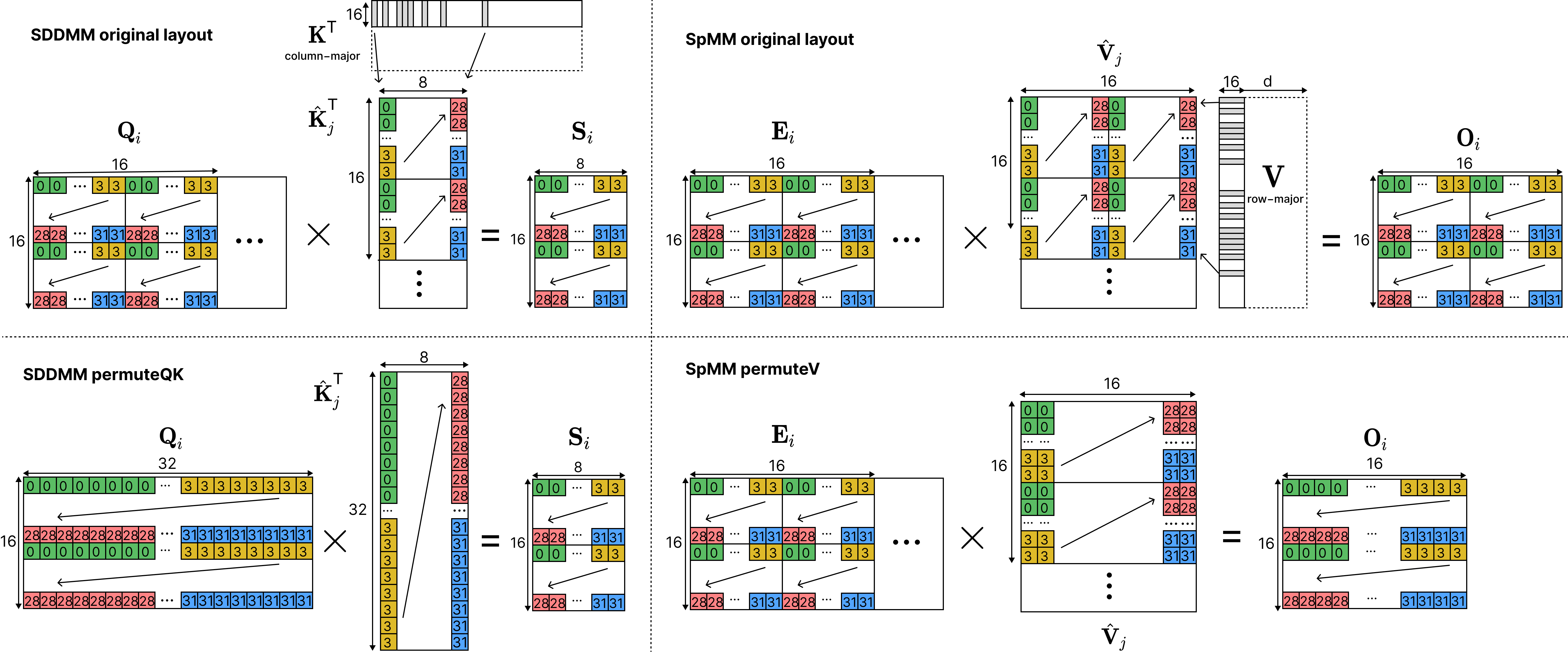
We further optimize memory access through register remapping — permuting column layouts of K and V to enable 128-bit coalesced loads instead of scattered 32-bit loads. We use the PTX mma interface to load operands directly from HBM into registers, bypassing shared memory for single-use data.
Results
We evaluate on NVIDIA A30 (Ampere, 56 SMs) and H100 (Hopper, 132 SMs) GPUs across 15 single-graph datasets and batched graphs from LRGB and OGB benchmarks.
3S Kernel Performance
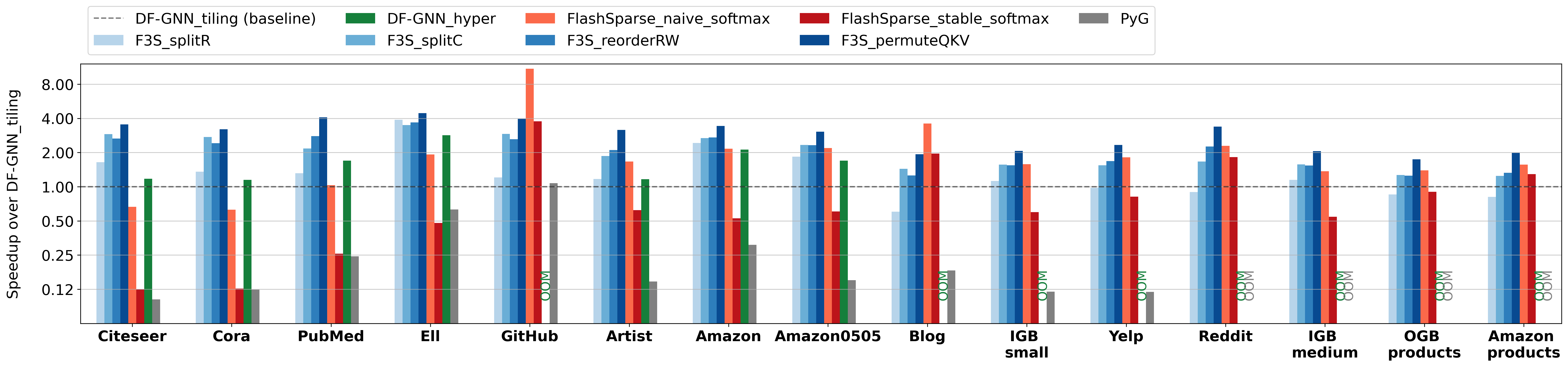
On single graphs, Fused3S consistently outperforms all baselines:

On batched graphs, the gains are even more pronounced:
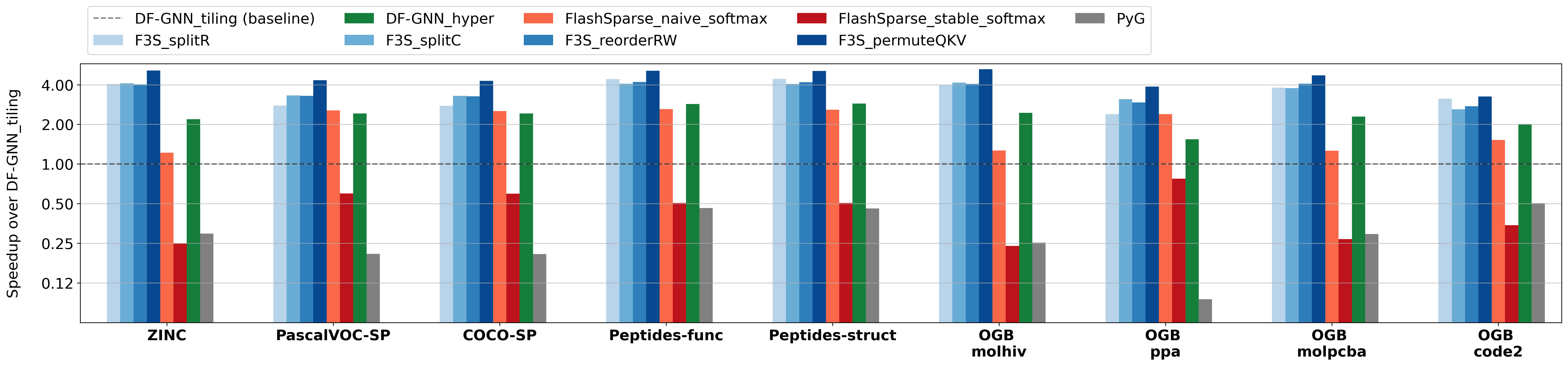

By avoiding materialization of the intermediate score matrix, Fused3S also reduces memory consumption, enabling execution on large graphs where other methods run out of memory.
End-to-End Graph Transformer Inference
Integrated into a 10-layer Graph Transformer model, Fused3S accelerates end-to-end inference:
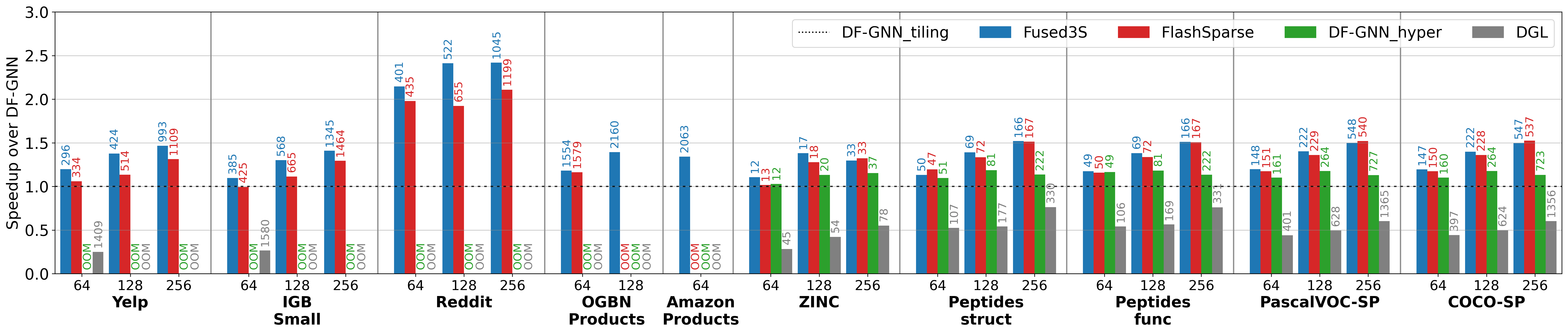
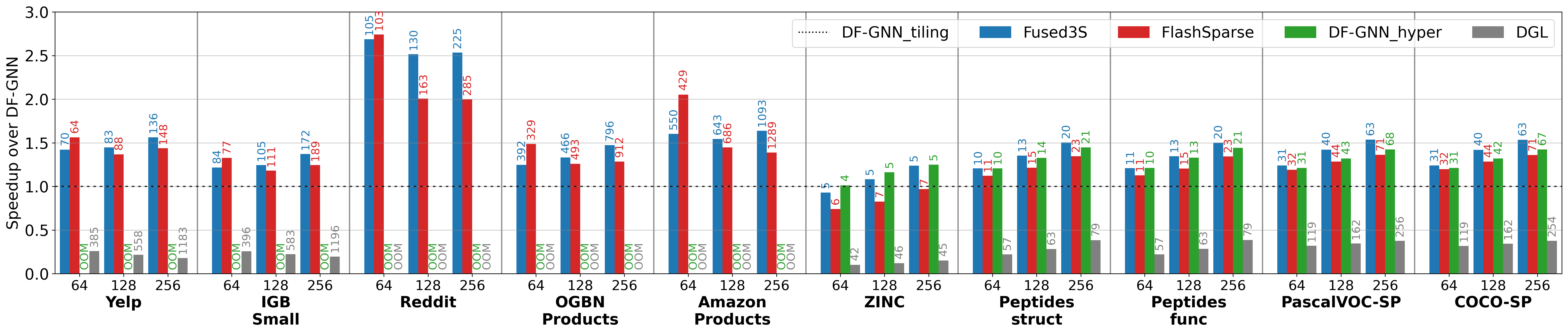
BibTeX
@inproceedings{li2025fused3s,
title = {Fused3S: Fast Sparse Attention on Tensor Cores},
author = {Li, Zitong and Chandramowlishwaran, Aparna},
booktitle = {Proceedings of the 2025 International Conference on Supercomputing (ICS)},
year = {2025},
doi = {10.1145/3721145.3730430}
}